
Dolphin X1 405B: Single Node Llama 405B Training
Overview
Llama 3.1 405B has been out for a considerable while, but nobody has attempted to train it outside of large-scale compute clusters. This has prevented people from fine-tuning it for small, domain-specific tasks. Using just Axolotl, we managed to train AllenAI’s post-train of Llama 3.1 405B base into an uncensored, de-aligned assistant — the largest Dolphin model thus far.
Why did you choose Tulu3 over Llama 3.1 Instruct?
In our internal testing, we found the Tulu-3 model to be better in conversational settings than Meta’s own instruct tune while still matching its performance.
Why did you choose Axolotl for fine-tuning over alternative frameworks like LlamaFactory/TorchTune/etc?
Axolotl is one of the simplest ways to fine-tune and has a lot of VRAM-saving options. It’s also easy to work with for beginners.
For starters, we wanted to warm up the model on a small amount of de-censorship/de-alignment data. This way, in the later offline-RL stage, the model would be able to output decensored responses. We made sure to double-check that the prompts we were training on weren’t in the KTO dataset.
Tulu 70B Experiments
Before we scaled up to 405B, we wanted to verify that our datasets and methods were up to par and would work at larger sizes. So we decided to do an experimental run on Tulu3-70B, as it had gone through a similar training process.
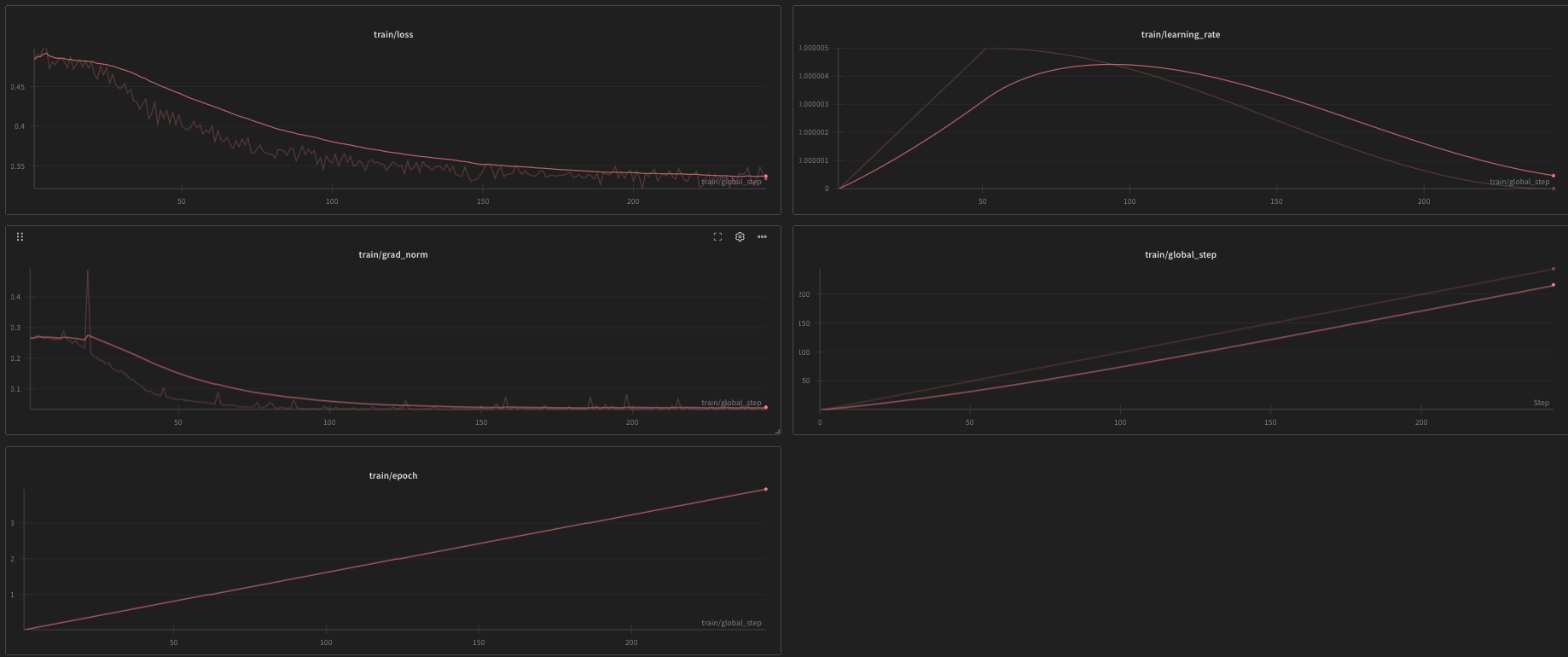
70B Tulu SFT run
For the data mix, we tested both our own internal training dataset mixed with other instruct datasets to help with catastrophic forgetting, but ultimately landed on just running with the refusal datasets as they provided the best “de-aligned” model.
Loss was lower than expected, possibly due to the model having domain knowledge of this type of prompt thanks in part to the safety data it was trained on. We ran for 2 epochs at an LR of 5e-6 (with cosine scheduling), 1.0 max grad norm, and 0.001 weight decay at an effective batch size of 128 @ 32K context, with a Rank 128/Alpha 256 LoRA allowing for higher batch sizes.
In testing, the model was remarkably decensored and achieved ~70% on our internal benchmark for testing model refusals and alignment. This warmup allowed us to proceed to the KTO phase.
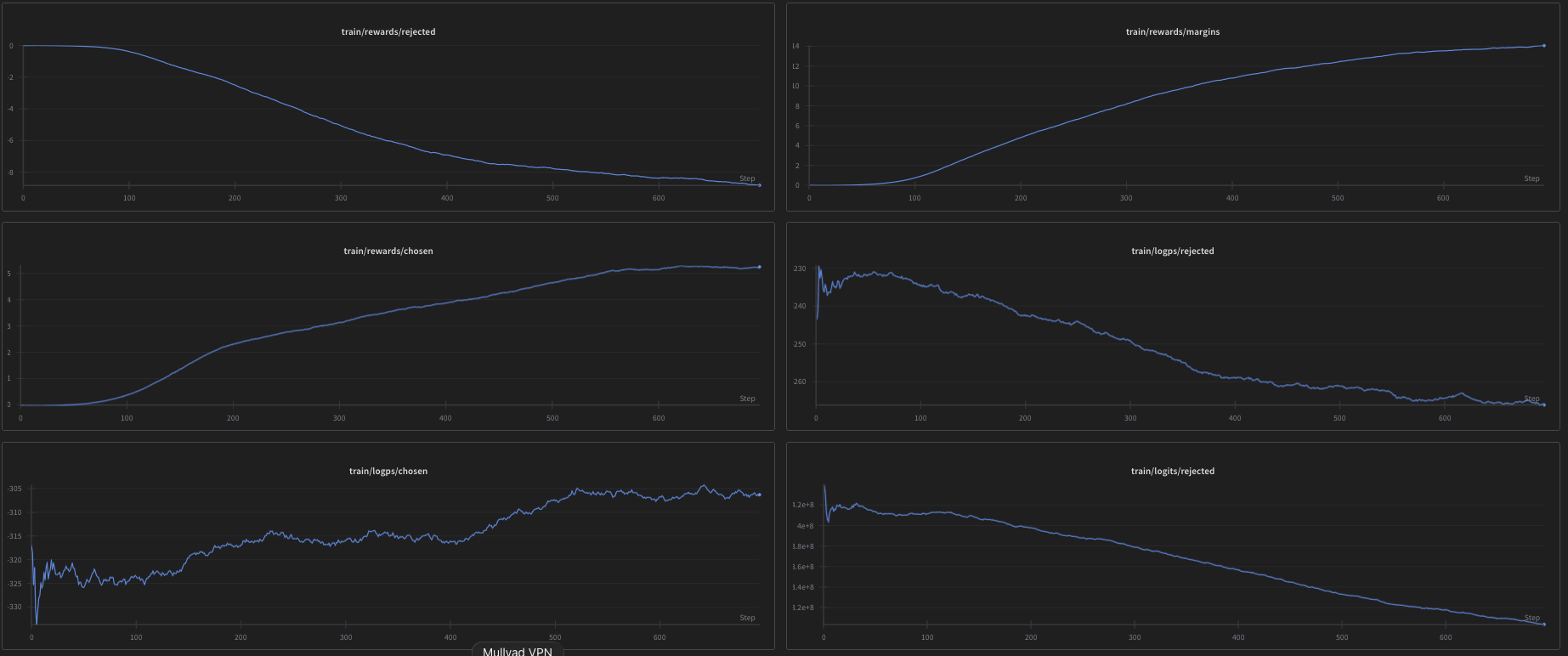
Tulu 70B KTO run
After some sweeps, we found that while including non-de-alignment datasets in the SFT mix hurt de-alignment performance, including instruct KTO datasets in the KTO mix was fine and the model still turned out decensored. This is due to how KTO works: KTO estimates the Kahneman-Tversky value, optimizing “good” outputs while trying to minimize “undesirable” outputs. KTO extracts a more generalized idea of what makes outputs preferable by aggregating patterns across large, diverse batches of data. This is why KTO needs batches between 64 and 128 to be successful.
Things to monitor during KTO runs are Rewards/Chosen and Rewards/Margins. If the margin between desirable and undesirable outputs rises and then plateaus throughout training, the model has stopped trying to distinguish between good/bad responses—meaning either the signal isn’t being absorbed OR it has learned as much as it can and is being over-trained. Thus, you should always practice early stopping and keep checkpoints on hand from every 100 or so steps.
We found our optimal settings to be: Rank 64 LoRA, Alpha 16 RSLoRA, no weight decay, 0.001 clip, 5e-6 LR, and 0.35 beta with standard weighting and 100 warmup steps.
Weighting adjustment should only be done if your dataset isn’t properly balanced 50/50 between rejected/accepted entries OR if the effect of one or the other needs to be emphasized.
LoRA saves on VRAM and allows for high batch sizes. Also, LoRA works wonders for RL and there isn’t much advantage to full-parameter fine-tuning.
We used 100 warmup steps because otherwise the initial warmup is unstable and sometimes you might end up with a chosen graph like this:
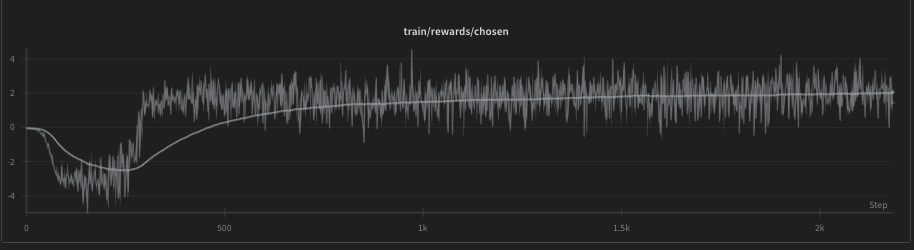
Arguably, you could experiment with lower warmup steps. We preferred to play it safe and use higher warmup to gradually ease the model into training.
We chose a clip of 0.001 because the large size means the model will often start to see the pattern of accepted/rejected early on, causing the run to quickly flatline before all the prompts have had a chance to be processed.
We chose 0.35 beta because it allowed the model to retain the instruct-following of the base SFT without adopting the same biases. 0.5 beta and higher usually resulted in overly censored models; lower than 0.3 resulted in the model being over-trained.
To go along with this, we ran with a higher 5e-6 LR since we had clipping in place to help prevent over-training, along with LoRA to reduce those effects.
The end result was one of our most uncensored models yet, which benched lower than the base 70B it was based on by about ~20%. This signaled to us that to reduce the gap, we should include more instruct data in the KTO phase.
70B hyperparameters overview
| Phase | LoRA R | LR | Batch Size | Clip | Beta | Weight decay |
|---|---|---|---|---|---|---|
| SFT 70B | 128 | 5e-6 | 128 | 1.0 (HF default) | - | 0.000 |
| KTO 70B | 64 | 5e-6 | 128 | 0.001 | 0.35 | - |
Training Dolphin X1 405B
We started the 405B train with just a small 200M token warmup using a Rank 128 LoRA with an alpha of 256. To fine-tune, we used:
- Paged AdamW 8-bit
- 8K context length (samples were no longer than 8K)
- Grad accumulation: 8
- Batch size: 1
- Liger + Cut Cross Entropy
- LR: 3e-6
- DeepSpeed ZeRO-3 with torch compile
- Gradient checkpointing
We were quite surprised that we didn’t need to offload the model to fit ZeRO-3. To fit a higher context length, you could possibly switch to offload checkpointing.
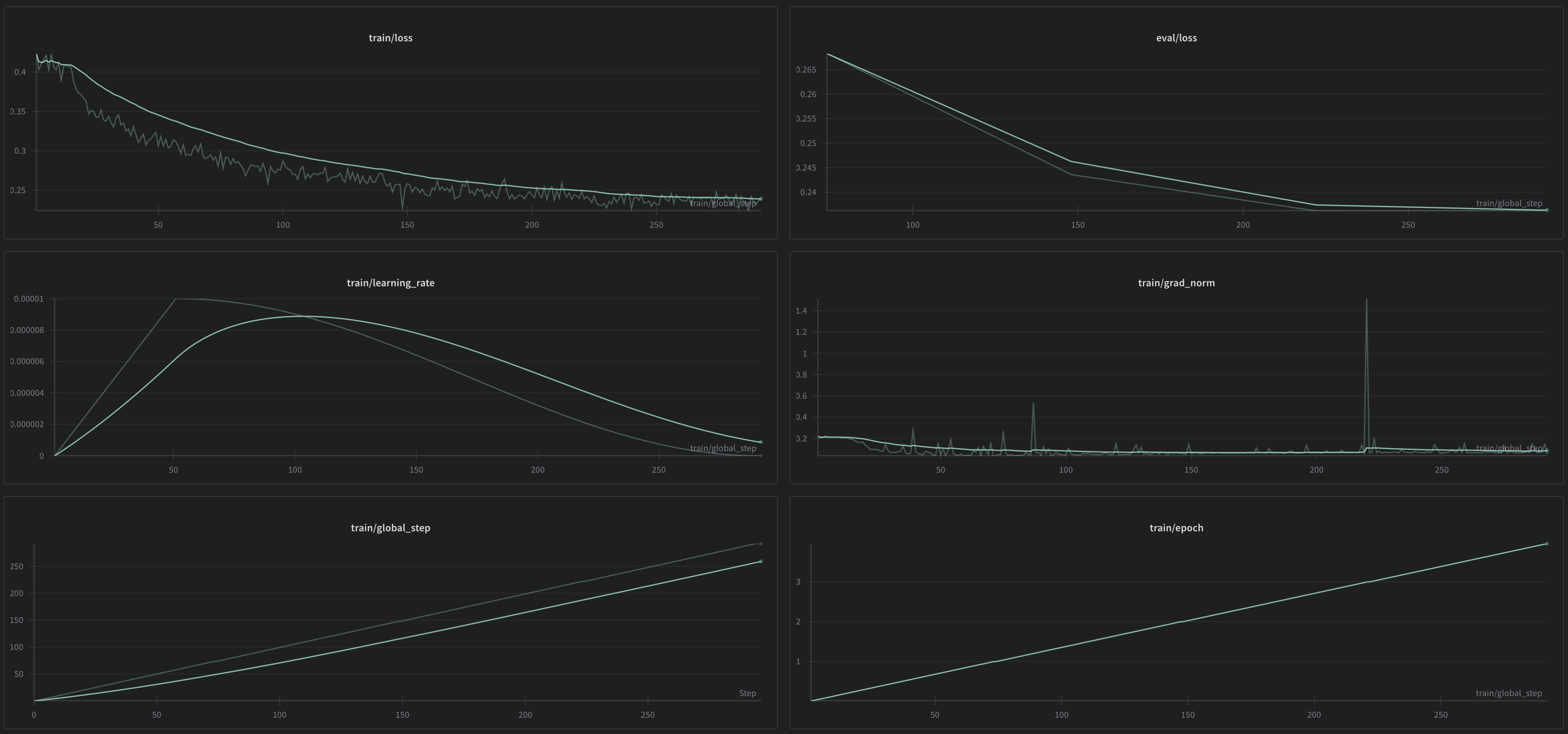
SFT 405B
Once again, as shown with the previous 70B, loss descended smoothly and gradients never spiked apart from a small spike to 1.4. This was due to both model size and the aforementioned safety data that helped the model fit to the de-censorship and de-alignment data.
By the end of the run, we found that the model now had the capacity to respond to harmful requests around 60% of the time. To further decensor it, we decided to apply offline RL.
KTO
We found that KTO was far more unstable in terms of VRAM usage than supervised fine-tuning. While you’d have initially lower VRAM allocation and usage, spikes on just one or two GPUs would cause the run to OOM even when there was plenty of VRAM on the other GPUs.
To get around this, we enabled offload-all for ZeRO-3. This allowed us to use a high batch size as well as a Rank 64 LoRA. However, this caused us to run into another issue: due to offload-all, we’d run into RAM OOMs when checkpointing. We solved this by changing "gather_16bit_weights_on_model_save": true to "gather_16bit_weights_on_model_save": false and manually converting the weights to 16-bit safetensors ourselves.
For hyperparameters, we chose:
- Effective batch size: 128
- 5e-6 LR
- 0.001 clip
- 100 warmup steps
- Default weighting
- AdamW 8-bit
And keeping with the lessons from the previous 70B, we included a lot more data in the KTO stage.
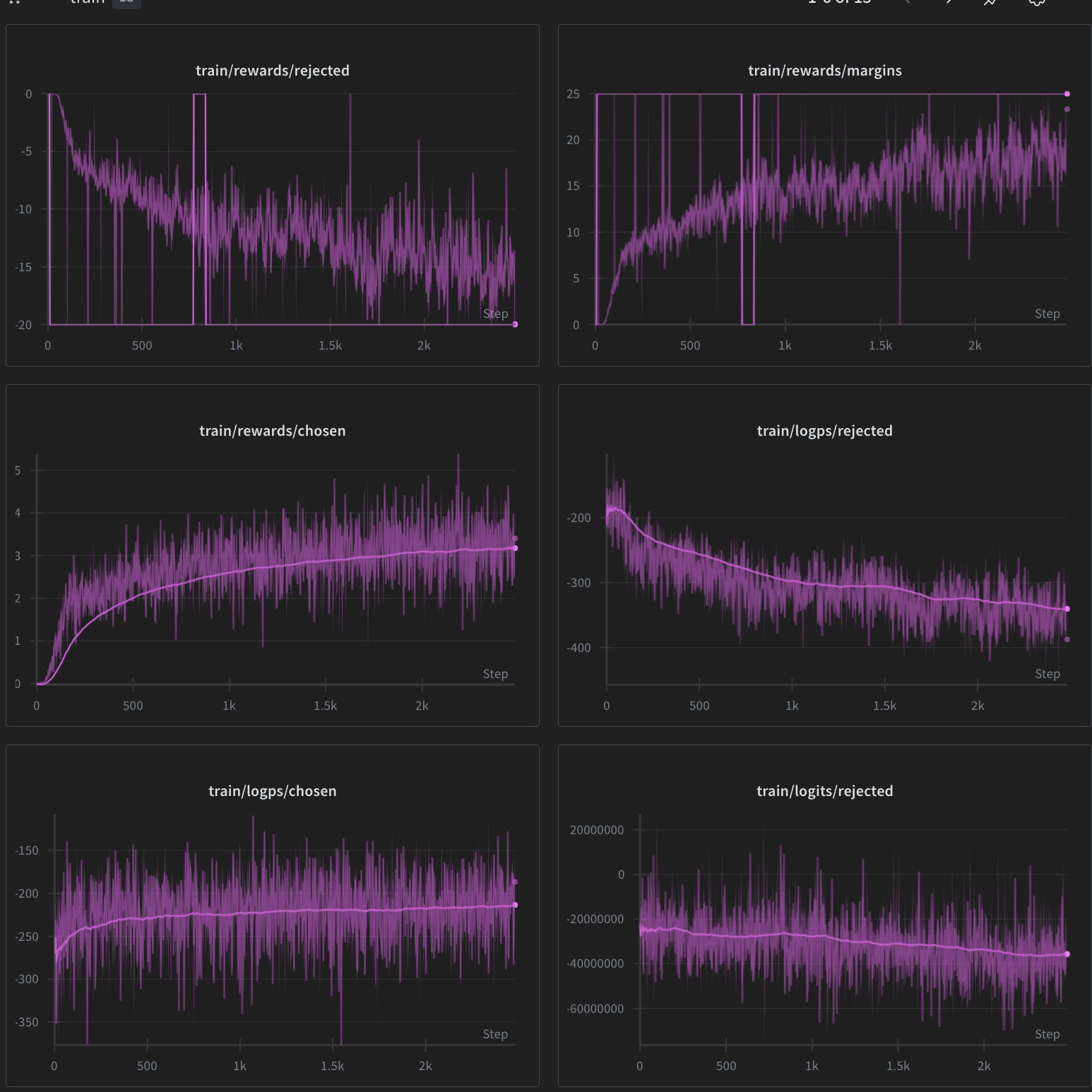
KTO 405B
During the run, we observed some instabilities that we later attributed to cut-off responses in our datasets. However, apart from that, the model kept improving toward the end and margins/rewards/chosen never flattened out.
The final result was a nice, decensored model that, during evaluation by testers, felt better than other 405B fine-tunes for general chat tasks.
405B Hyperparameters
| Phase | LoRA R | LR | Batch Size | Clip | Beta | Weight decay |
|---|---|---|---|---|---|---|
| SFT 405B | 128 | 3e-6 | 64 | 1.0 (HF default) | - | 0.001 |
| KTO 405B | 64 | 5e-6 | 128 | 0.001 | 0.35 | - |
Evaluation
We evaluated model responses on Nous Research’s Refusalbench and found it to be SOTA with 100% compliance rate for all requests within the dataset.
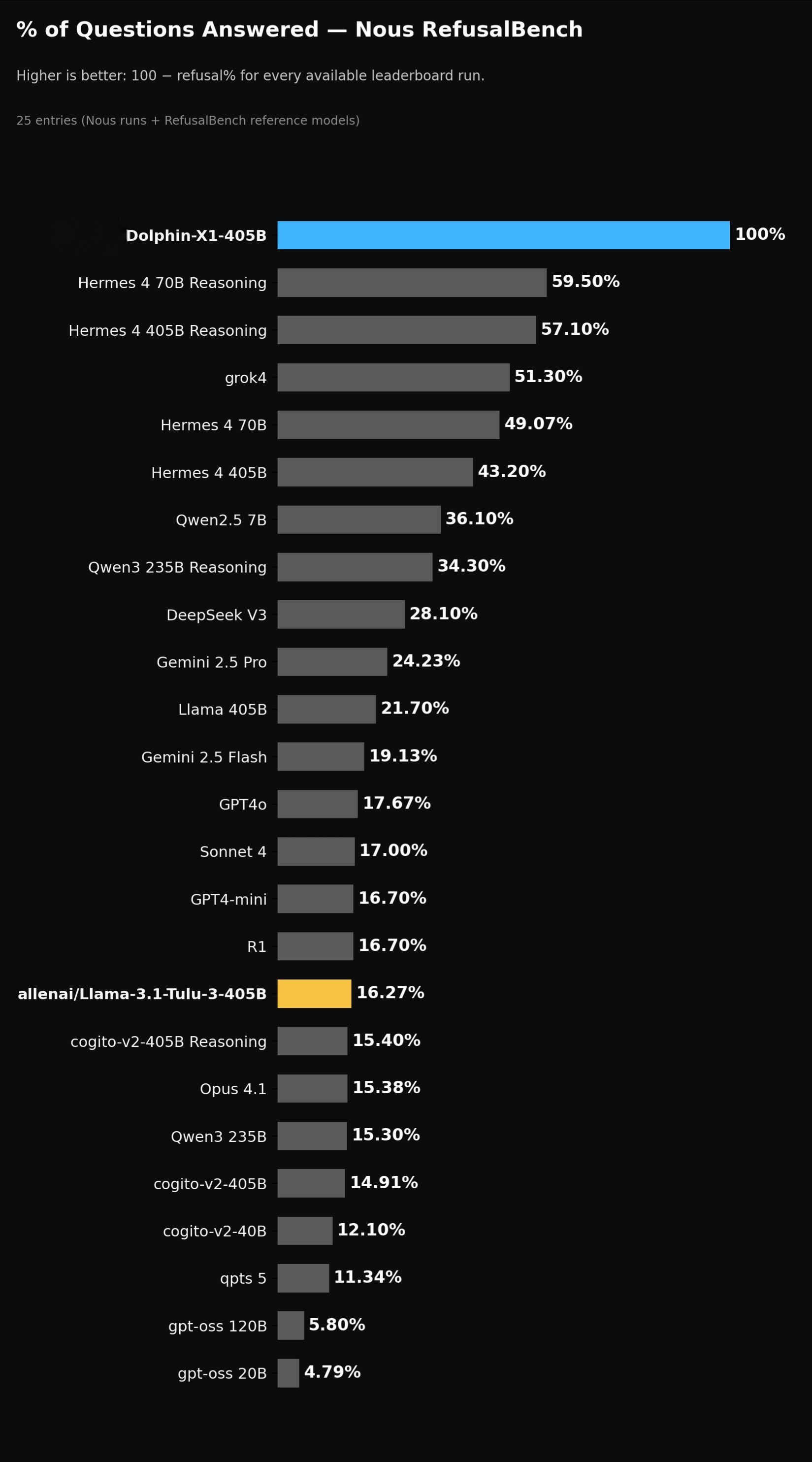
Conclusion
We’ve shown that training L3.1 405B doesn’t require multiple nodes and can be done cheaply and effectively using just 8xB200s, (Graciously provided by https://lium.io )
By using Axolotl, LoRA, and DeepSpeed ZeRO-3, we were able to successfully de-align AllenAi’s Tulu Finetune of L3.1 405B The key takeaways from our runs:
- Validate approaches before scaling.
- Light SFT and a higher focus on RL is crucial for de-alignment, Former approaches to this take have relied solely on SFT.
- Read training documentation: Alot of VRAM saving measures can be applied, Most of them You probably don’t even know of, Read the documentation of whatever trainer you are using to look for ways in which you can save VRAM.
For anyone looking to fine-tune large models on specialized tasks, We provide a proven workflow, In the future, We hope to improve our usage of RL to continue building strong, de-aligned models.